
Paper summary: BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension , Oct. 2019. (link)
Why is this important?
In this paper, Lewis et al. present valuable comparative work on different pre-training techniques and show how this kind of work can be used to guide large pre-training experiments reaching state-of-the-art (SOTA) results.
What does it propose?
The authors propose a framework to compare pre-training techniques and language model (LM) objectives. This framework focuses on how these techniques can be viewed as corrupting text with an arbitrary noising function while the Language Model is tasked with denoising it. After some comparative experiments using this framework, BART is introduced as a transformer-based LM that reaches SOTA performance.
How does it work?
The Framework

- Apply a noising function to the text
- The language model attempts to reconstruct the text
- Then calculate the loss function (typically cross entropy over the original text) and then back-propagate the gradients and update the model’s weights.
Comparing different text-noising techniques and LM Objectives

In the first experiment, using the framework they introduced at the beginning of the article, the authors compared different pre-training techniques and LM objectives on a smaller than usual model, BART-base. The model uses a 6 layered, transformer-based, seq2seq architecture for autoencoding as introduced by Vaswani et al. The pre-training techniques compared in the experiments can be divided between those that work at the token level and those that work at the sentence level:
Token Masking: random tokens are sampled and replaced with [MASK]
Token Deletion: similar to masking but the sampled tokens are deleted and the model has to add a new token in their place.
Token Infilling: a number of text spans, i.e. contiguous group tokens, are sampled, and then they are replaced by the [MASK] token.
Sentence Permutation: random shuffling of the document’s sentences.
Document Rotation a token is chosen randomly to be the start of the document, the section before the starting token is appended at the end.
Intuitively, the techniques that work at the sentence level should help the LM learn the different roles of sentences in a paragraph or longer text and in the process help dealing with natural language generation(NLG) tasks.
Besides the pre-training techniques, the authors also compare different LM objectives focusing on the ones used by BERT and GPT as well as techniques that tried to incorporate the best of both worlds:
Autoregressive, left to right, LM (GPT-2)
Masked LM (BERT) replace 15% of the token with the [MASK] token and predict the corresponding words.
Permuted LM (XLNet) left to right, autoregressive LM training but with the order of the words to predict chosen at random.
Multitask Masked LM (UniLM) combination of right-to-left, left-to-right and bidirectionality. ⅓ of the time using each with shared parameters.
Masked Seq2Seq (MASS) masking a span containing 50% of the tokens and train to predict the masked tokens.
Results of the first experiment
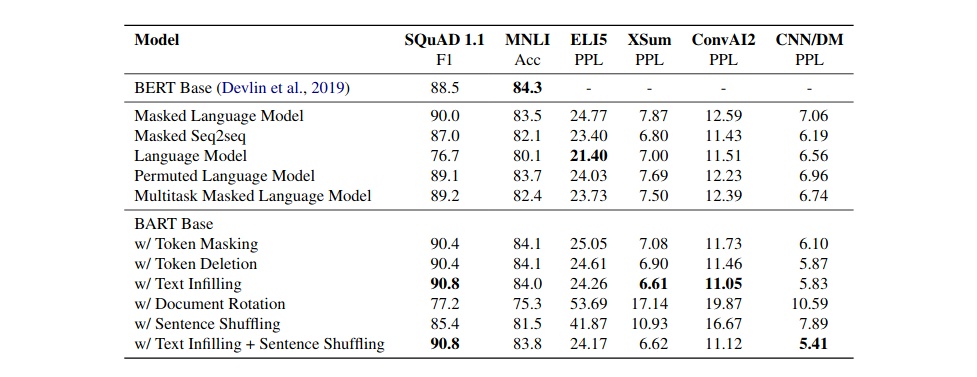
From the results of this first experiments the authors draw some important conclusions.
Token masking is crucial
Only the configurations with token masking or its variations achieve consistently great performance on different tasks.
Left-to-right pre-training improves NLG
The classical LM objective despite not doing well in inference or question answering tasks, achieves SOTA on ELI5 (Explain Like I’m 5).
Bidirectional encoders are crucial for QA
Ignoring future context hinders the performance of left-to-right models.
While pre-training techniques and LM objectives are important, the authors make note of the fact that they do not provide the full picture. They report that their permuted language model performs much worse than XLNet because BART lacks some of the valuable architectural innovations introduced in XLNet.
Results of the large-scale pre-training experiment
After the comparative experiment, the authors trained a 12 layered, transformer-based architecture for autoencoding, and using similar hyperparameters to RoBERTa. They used both a form of token masking at 30% and sentence permutation as pre-training text-noising techniques and run the model on 160GB of news, books, stories, and web text, similar to what’s done in RoBERTa.
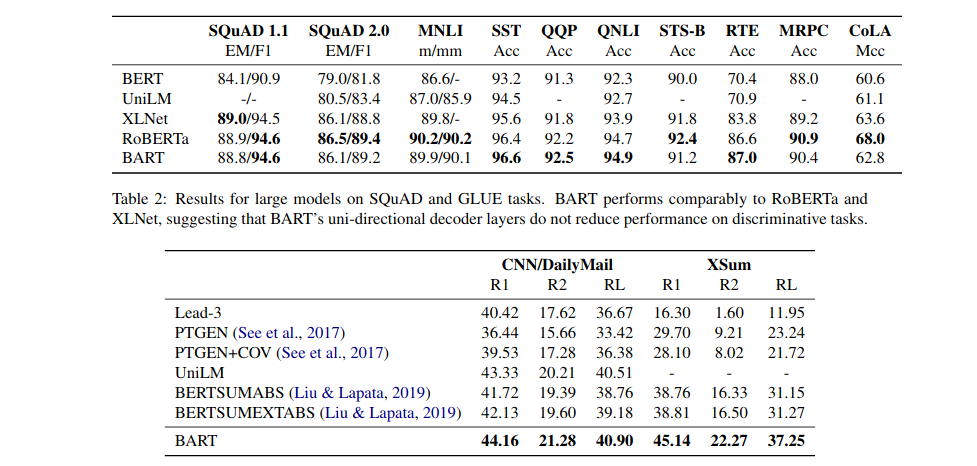
BART performs best in abstractive summarization tasks especially in the XSum benchmark that contains very few examples of summaries where phrases are present both in the summary and the original text. Besides surpassing the previous best systems in summarization by a considerable margin, BART does well also in natural language inference (NLI) tasks and QA, where it is on par with SOTA results.
Qualitative Analysis
The paper also features examples of the summaries produced by BART that can really give a sense of how well it does on the XSum dataset:

If you want to summarize some text of your own we have set up a Google Colab notebook using the Hugging Face library.
BART: Are all pretraining techniques created equal? was originally published by DAIR.AI at DAIR.AI on May 11, 2020.